Không phải tất cả AI đều giống nhau
Artifacial Inteligence hay trí tuệ nhân tạo là công nghệ mô phỏng quá trình suy nghĩ, học tập của con người cho máy móc. Đây là lĩnh vực quan trọng của ngành Khoa học Máy tính và được chia làm 2 loại là: Trí tuệ nhân tạo mạnh - Strong AI (Artifacial General Inteligence) và Trí tuệ nhân tạo yếu - Weak AI (Artifacial Specific Intelligence).
Strong AI là khái niệm Trí tuệ nhân tạo đươc xây dựng có khả năng suy nghĩ như con người, tự nhận thức và tự nhận diện bản thân. Strong AI là đề tài hấp dẫn trên các bộ phim viễn tưởng nhưng thực tế chúng ta mới chỉ có cơ hội tiếp xúc với Weak AI, loại trí tuệ nhân tạo được thiết kế để mô phỏng một số chức năng của con người. Ví dụ, AI chơi cờ có thể đánh bại các nhà vô địch, hay AI lái xe trên hệ thống xe tự hành...
AI và mối quan hệ mật thiết với dữ liệu
Ngày nay, con người sản sinh ra lượng dữ liệu vô cùng lớn. Đồng thời, công nghệ hỗ trợ cho Cách mạng 4.0 đã xóa bỏ rào cản trong việc thu thập Big Data. Chúng ta đang khai thác giá trị lớn nhất là thông tin và tri thức từ dữ liệu. Trí tuệ nhân tạo là công cụ chính để phân tích, trích rút thông tin từ nhiều loại dữ liệu khác nhau. TS. Hoài nhận định: "AI mô phỏng cho cách chúng ta nhận diện và đưa ra dự báo. AI giúp tối ưu hoạt động của con người. Hiện nay, AI cần rất nhiều dữ liệu để làm được điều đó".
TS. Hoài cho biết AI và dữ liệu có quan hệ mật thiết với nhau: "Những công nghệ AI khai thác dữ liệu (data mining) hiện nay như học sâu (deep learning) cần lượng dữ liệu rất lớn. Chính vì thế, các hệ thống AI hiện nay là AI hướng dữ liệu (data driven AI)".
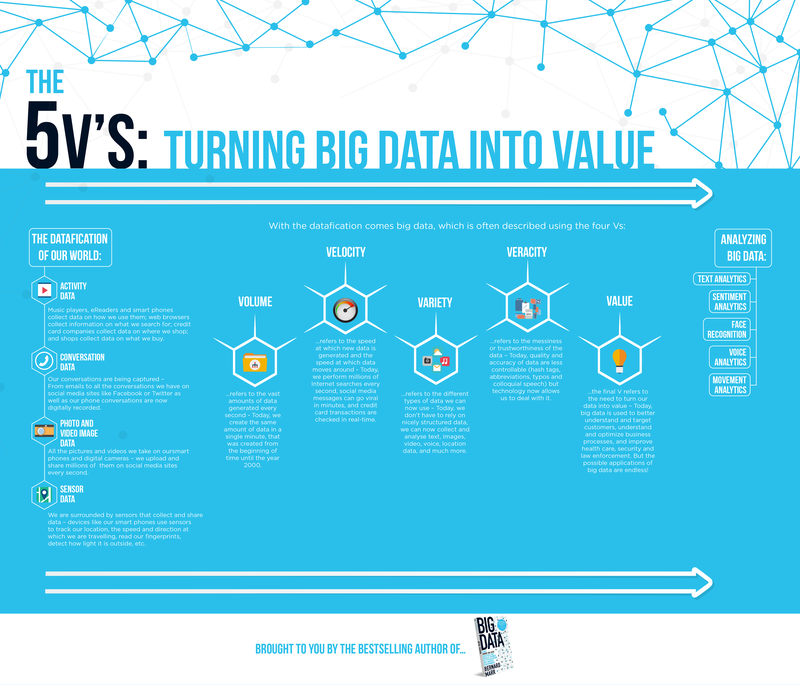 |
Dữ liệu mang đặc trưng phi truyền thống. Trong đó, chất lượng dữ liệu được quyết định bởi nguyên tắc 5“V”, bao gồm: Value - Giá trị, Velocity - Tốc độ, Volume - Số lượng, Veracity - Tính chính xác và Variety - Tính đa dạng. Xử lý dữ liệu lớn (Big Data) cần thực hiện qua nhiều tiến trình và trí tuệ nhân tạo chỉ đảm đương giai đoạn cuối. Vì vậy, AI hướng dữ liệu không chỉ phụ thuộc vào số lượng mà còn cần rất nhiều ở chất lượng dữ liệu.
TS. Hòa cho biết các dự án để phân tích dữ liệu lớn phụ thuộc vào AI có thể tổng kết bằng một công thức: Big Data Analytic = 80% Data Engine + 20% Data Analysis. TS. Hoài nói: "Có thể thấy rằng trong tiến trình từ khi lấy dữ liệu đến khi trích xuất được thông tin, tri thức từ dữ liệu khổng lồ, có đến 80% quy trình này liên quan đến quản trị dữ liệu, trong đó có quản lý chất lượng của dữ liệu".
Thiên lệch dữ liệu và hậu quả khó lường đối với AI
Trong quá trình phân tích và sử dụng dữ liệu, thật khó để định nghĩa chính xác khái niệm dữ liệu chất lượng tốt. Ông Hoài chỉ rõ rằng: “Một dữ liệu chất lượng là dữ liệu phù hợp cho nhu cầu của người cần dữ liệu”, nghĩa là chất lượng dữ liệu chỉ bộc lộ trong cách thức trình bày và cách con người truy cập sử dụng dữ liệu. Đặc tính chung của dữ liệu là độ chính xác, tin cậy, khách quan. Dữ liệu được coi là khách quan khi trích xuất từ quá trình doanh nghiệp tương tác với khách hàng. Dữ liệu mang tính chủ quan như lấy ý kiến khảo sát cá nhân.
Trong công nghệ Trí tuệ nhân tạo và học máy (machine learning) tồn tại 1 ngạn ngữ nổi tiếng "GIGO" (Garbage in – Garbage out). Nó mô tả chất lượng thông tin đầu vào không thể vượt quá chất lượng thông tin của đầu ra. Hiện nay, một trong những thách thức đối với AI, hay cụ thể hơn là AI hướng dữ liệu là sự thiên lệch dữ liệu (data bias). Về bản chất của thiên lệch về dữ liệu là một trong những vấn đề nghiêm trọng của chất lượng dữ liệu, khi dữ liệu sử dụng để huấn luyện hệ thống AI mang tính thiên lệch.
Theo thống kê của Đại học Tài chính Harvard, nước Mỹ tổn thất Mỹ 3 nghìn tỷ USD vì dữ liệu thiên lệch. Năm 2015, Google I/O tạo ra một cú sốc khi nhận diện khuôn mặt trong ảnh mang tính chất phân biệt chủng tộc vì dữ liệu dùng để huấn luyện hệ thống AI quá ít ảnh người da màu. Năm 2017, IBM Watson - Hệ thống AI hỗ trợ chẩn đoán và điều trị đã bị nhiều bệnh viện tố cáo là đưa cảnh báo không chuẩn xác. Nguyên nhân chính là do các kỹ sư xây dựng hệ thống của IBM Watson Technology đã giả mạo bệnh án để huấn luyện cho AI. Tất cả sự cố trên được tạo ra bởi dữ liệu thiên lệch.
Càng ngày chúng ta càng sống phụ thuộc vào công nghệ hướng dữ liệu, đưa ra những quyết định nhờ sự trợ giúp của AI. Tạp chí The National thậm chí còn cho biết Trung Quốc đang phát triển hệ thống đánh giá điểm tín dụng xã hội - Social Predicting System, dùng AI để phân tích Big Data ra quyết định chấp nhận hay từ chối mỗi công dân vào hoạt động của xã hội phụ thuộc vào hành vi và điểm tín dụng xã hội đó.
“Vậy điều gì sẽ xảy ra nếu quyết định dựa trên dữ liệu chất lượng kém, bị thiên lệch. Lấy giả thiết, con tôi không được vào cấp 3 vì hệ thống AI đánh giá công dân đánh giá tôi là người tệ hại. Do có một lần hệ thống CCTV nhận diện nhầm tôi và một kẻ tội phạm. Vậy ai sẽ chịu trách nhiệm? Trí tuệ nhân tạo, dữ liệu hay ai?” Đây là câu hỏi không chỉ của TS. Hoài mà còn là thử thách khó khăn nhân mà nhân loại sẽ phải đối mặt trong quá trình phát triển trí thông minh nhân tạo phục vụ con người.
 |
|
ông Pierre Bonnet, Giám đốc vận hành Orchestra Networks, Giám đốc điều hành Orchestra Networks Việt Nam nói về vai trò của Dữ liệu lớn và AI
|
Theo ông Pierre Bonnet, Giám đốc vận hành Orchestra Networks, Giám đốc điều hành Orchestra Networks Việt Nam: “Ranh giới giữa ứng dụng tích cực hoặc tiêu cực của Big Data và AI rất mong manh. Một mặt, xã hội tiếp tục tăng trưởng chóng mặt để đáp ứng nhu cầu của mình bằng cách loại bỏ các ảnh hưởng từ bên ngoài, và Big Data và AI được sử dụng để theo đuổi một sự phát triển không bền vững cho hành tinh này. Mặt khác, xã hội sử dụng Big Data và AI để thúc đẩy tăng trưởng tương thích với một hành tinh bền vững, phục vụ tất cả mọi người như nhau, và tận dụng lợi thế của việc quản lý kiến thức tốt hơn”.